
分布式网络爬虫管理平台Crawlab
本文题图背景由 AI 生成;
昨天的《视频搜索与观看平台LibreTV》发了几次都没有成功
之后在简介部分做了大量删减,才得以通过,没弄明白是什么关键词触发的。完整版请移步老苏的博客,如果还不知道博客地址,可以去微信公众号后台问 AI 客服
简介
什么是 Crawlab ?
Crawlab是强大的 网络爬虫管理平台(WCMP),它能够运行多种编程语言(包括Python、Go、Node.js、Java、C#)或爬虫框架(包括Scrapy、Colly、Selenium、Puppeteer)开发的网路爬虫。它能够用来运行、管理和监控网络爬虫,特别是对可溯性、可扩展性以及稳定性要求较高的生产环境。
主要特点
- 多语言支持:
Crawlab可以管理使用Python、NodeJS、Go、Java、PHP等多种编程语言编写的爬虫,适用于多种爬虫框架,如Scrapy、Puppeteer和Selenium。 - 分布式架构:
Crawlab由一个主节点和多个工作节点组成,支持水平扩展,可以同时处理多个爬虫任务。 - 用户友好的界面:提供美观的前端界面,使用户能够轻松管理爬虫、任务、调度和结果导出等功能。
- 集成与扩展性:
Crawlab提供SDK,方便用户将爬虫集成到平台中,同时支持多种数据存储和处理方式。 - 开源与社区支持:
Crawlab是开源项目,拥有活跃的社区支持,用户可以通过讨论组和文档获取帮助。
Crawlab 的目标是简化爬虫管理过程,提高开发效率,适合企业和个人开发者使用。
安装
在群晖上以 Docker 方式安装。
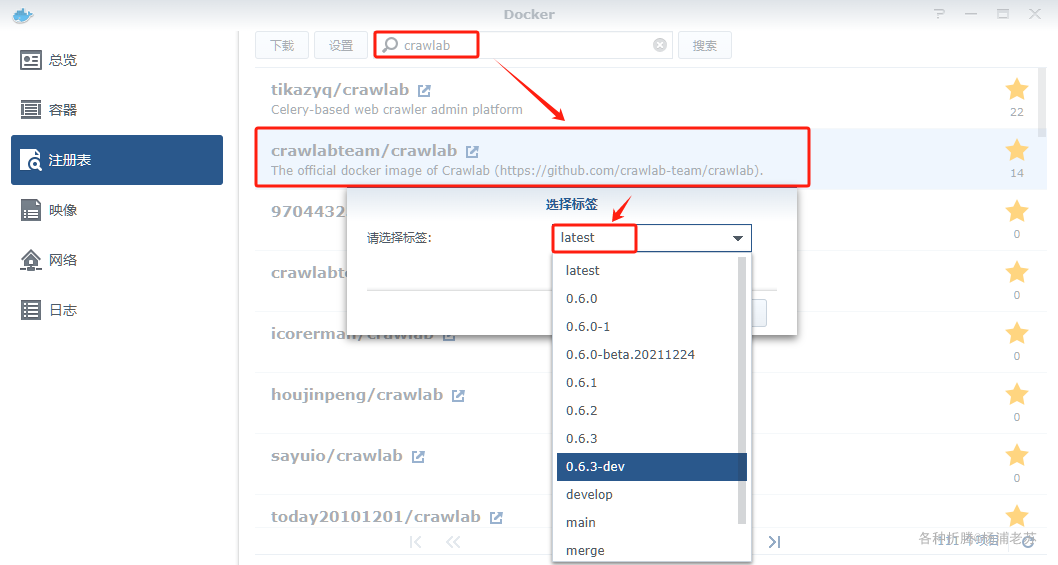
在注册表中搜索 crawlab ,选择第二个 crawlabteam/crawlab,版本选择 latest。
latest版本没有直接对应的版本,但是从时间看,应该在0.6.3-dev之后;
参照官方的示例,采用了一个主节点 + 2 个工作节点的模式,将下面的内容保存为 docker-compose.yml 文件
1 | version: '3.3' |
然后执行下面的命令
1 | # 新建文件夹 crawlab 和 子目录 |
运行
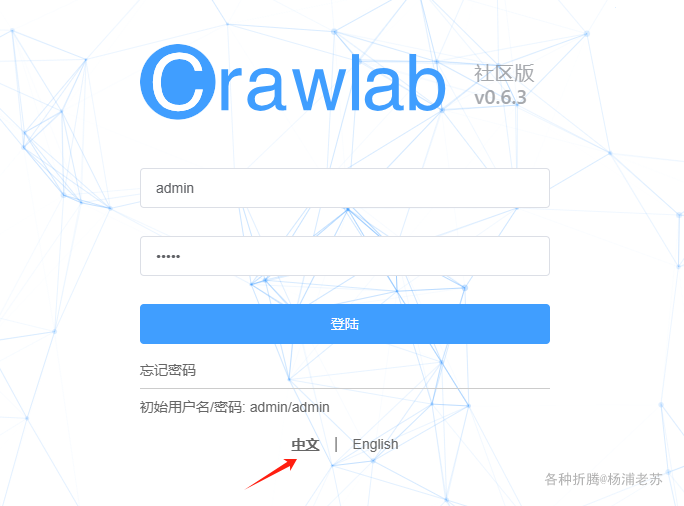
在浏览器中输入 http://群晖IP:8235 就能看到登录界面

默认账号、密码为 admin/admin
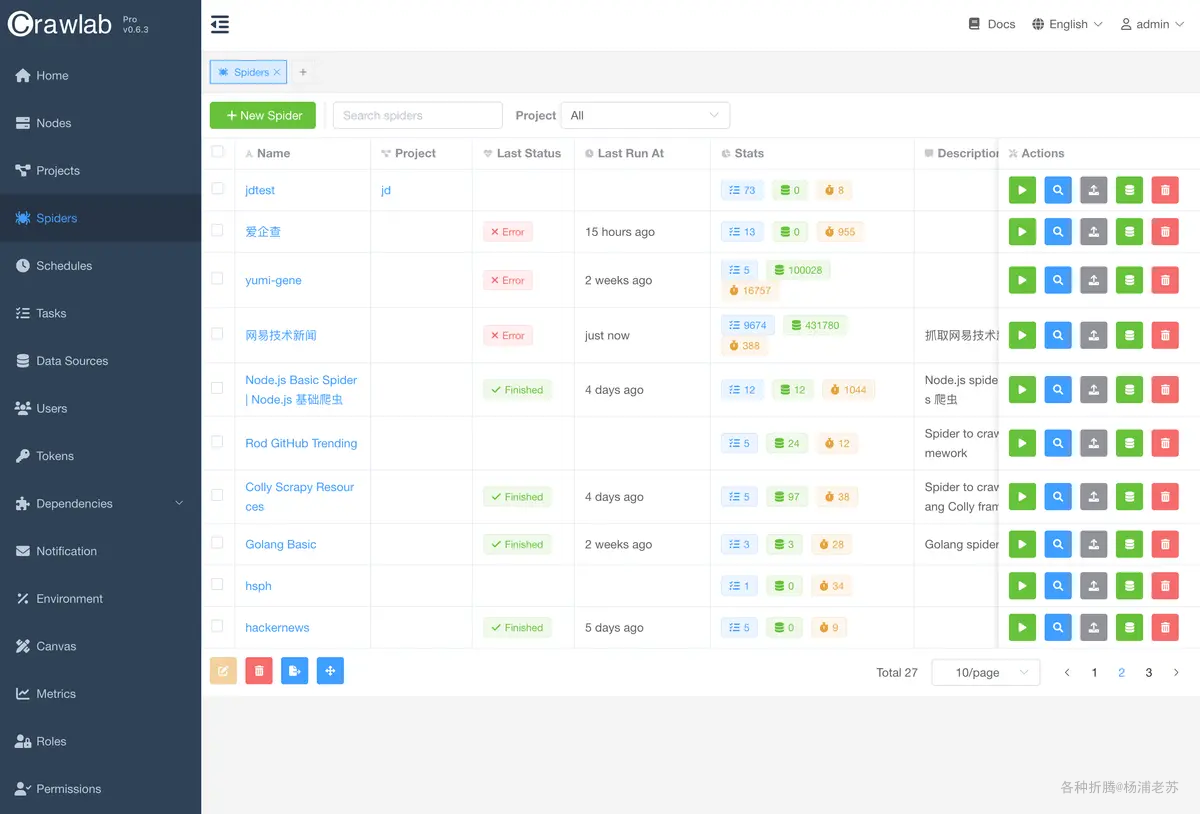
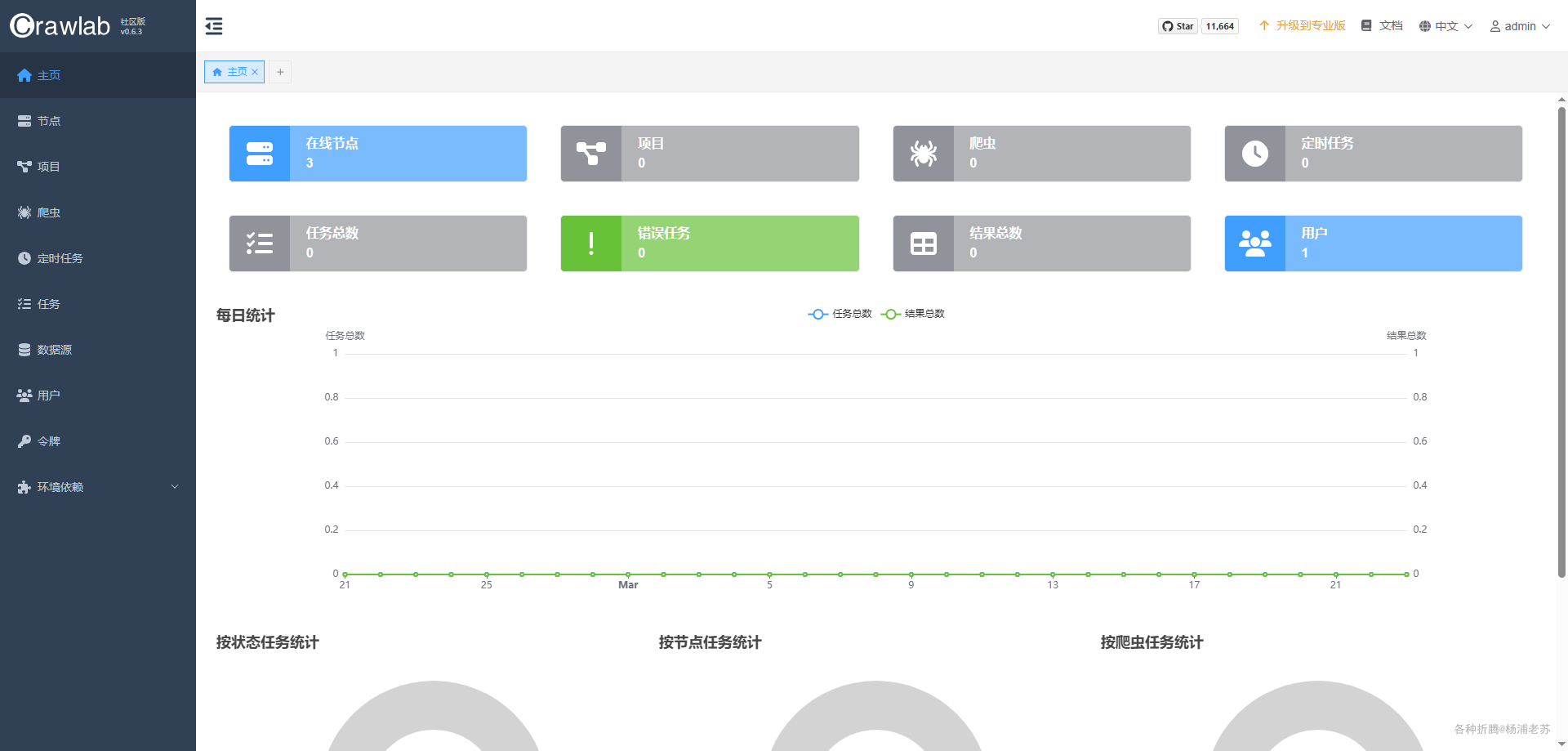
登录成功后的主界面
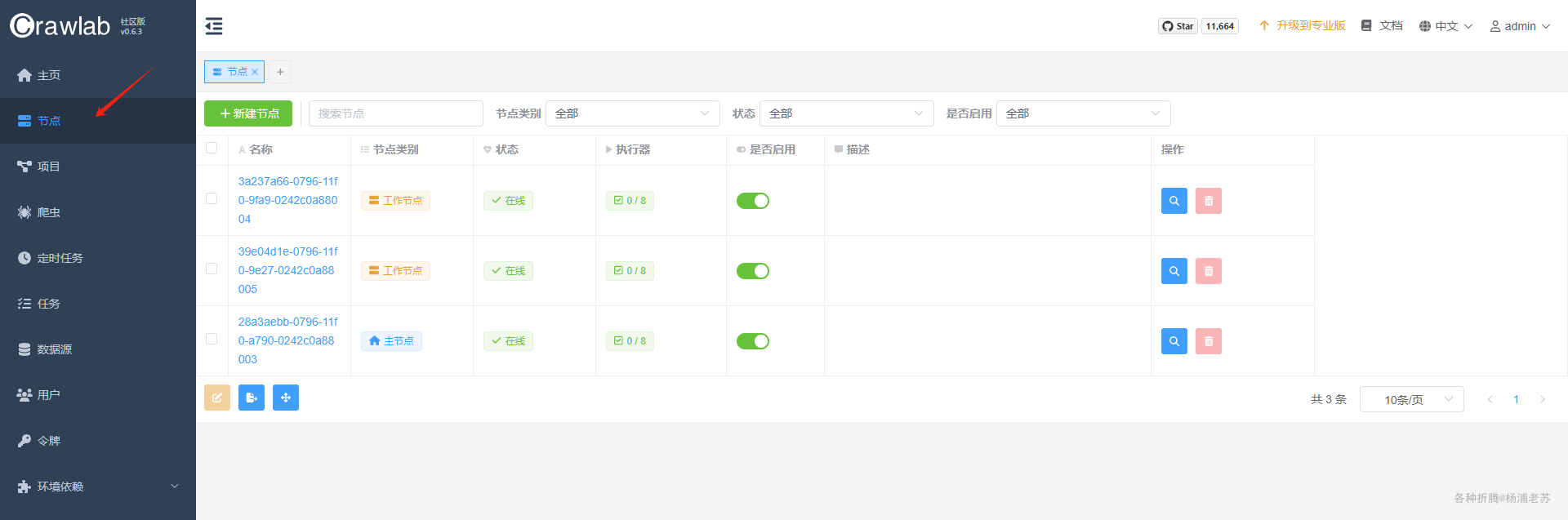
进入 节点,可以查看主节点和工作节点的状态
接下来就是如何使用了,老苏建议从官方的《快速教程》开始,地址:https://docs.crawlab.cn/zh/guide/basic-tutorial/
但看起来爬虫需要写代码才行,虽然现在有 AI 的加持,但还是把老苏劝退了 😂
参考文档
crawlab-team/crawlab: Distributed web crawler admin platform for spiders management regardless of languages and frameworks. 分布式爬虫管理平台,支持任何语言和框架
地址:https://github.com/crawlab-team/crawlabCrawlab - 强大的网络爬虫管理平台
地址:https://www.crawlab.cn/zh介绍
地址:https://docs.crawlab.cn/zh/guide/