
搭建本地人工智能框架LocalAI
什么是 LocalAI
LocalAI是一个用于本地推理的,与OpenAI API规范兼容的REST API。它允许您在本地使用消费级硬件运行LLM(不仅如此),支持与ggml格式兼容的多个模型系列。不需要GPU。
最吸引老苏的有两点,一个是不需要 GPU,另一点上可以使用消费级硬件,所以准备搭一个试试,至于后续用来干什么,到时候再说
官方倒是提供了很多示例,比较常见的是机器人,比如:Discord bot、Slack bot 或者 Telegram bot
安装
在群晖上以 Docker 方式安装。
镜像下载
官方没有在 docker hub 上发布镜像,而是发布到了 quay.io
用 SSH 客户端登录到群晖后,依次执行下面的命令
这个版本是
cpu版本,如果你有gpu,可以下载支持cuda的版本;
1 | # 新建文件夹 localai 和 子目录 |
镜像文件比较大(大约 13G ),如果拉不动,也可以试试 docker 代理网站:https://dockerproxy.com/,但是会多几个步骤
1 | # 如果拉不动的话加个代理 |
下载完成后,可以在 映像 中找到

docker-compose 安装
将下面的内容保存为 docker-compose.yml 文件
1 | version: '3.6' |
然后执行下面的命令
1 | # 将 docker-compose.yml 放入当前目录 |
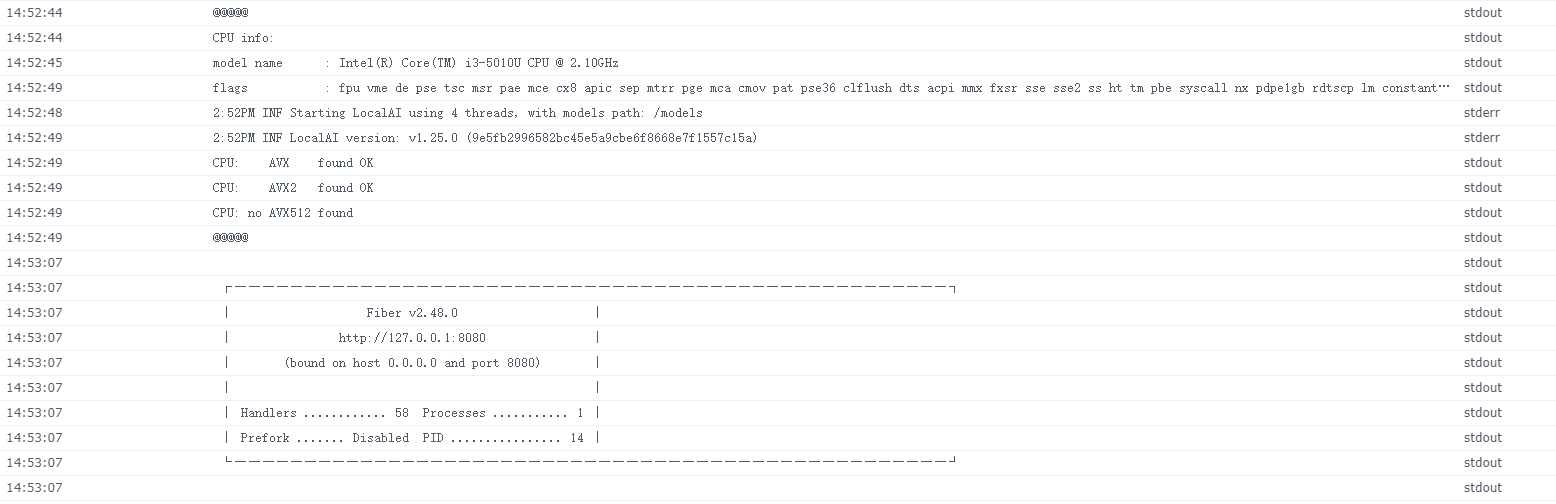
从日志可以看到,和 Serge 一样,需要 AVX2 指令兼容的 CPU
模型文件
如果你运行过 Serge,原来下载的 gpt4all.bin 文件是可以直接用的,因为 LocalAI 与 llama.cpp 支持的模型兼容
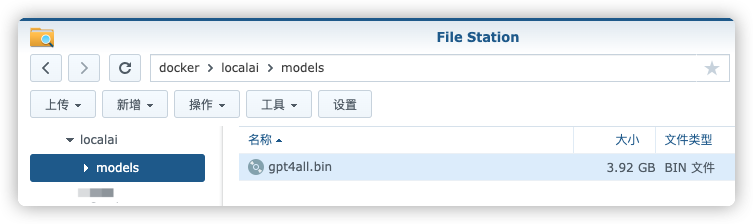
否则的话,需要自己下模型文件
老苏把
gpt4all.bin文件放在了阿里云盘: https://www.aliyundrive.com/s/GQqs39iipya
Open LLM 基准测试中表现最佳的模型列表排行榜:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
请记住,与 LocalAI 兼容的模型必须以 ggml 格式进行量化
老苏目前只测试了
gpt4all.bin,所以没法给大家提供指导意见,不要问我下哪个模型。
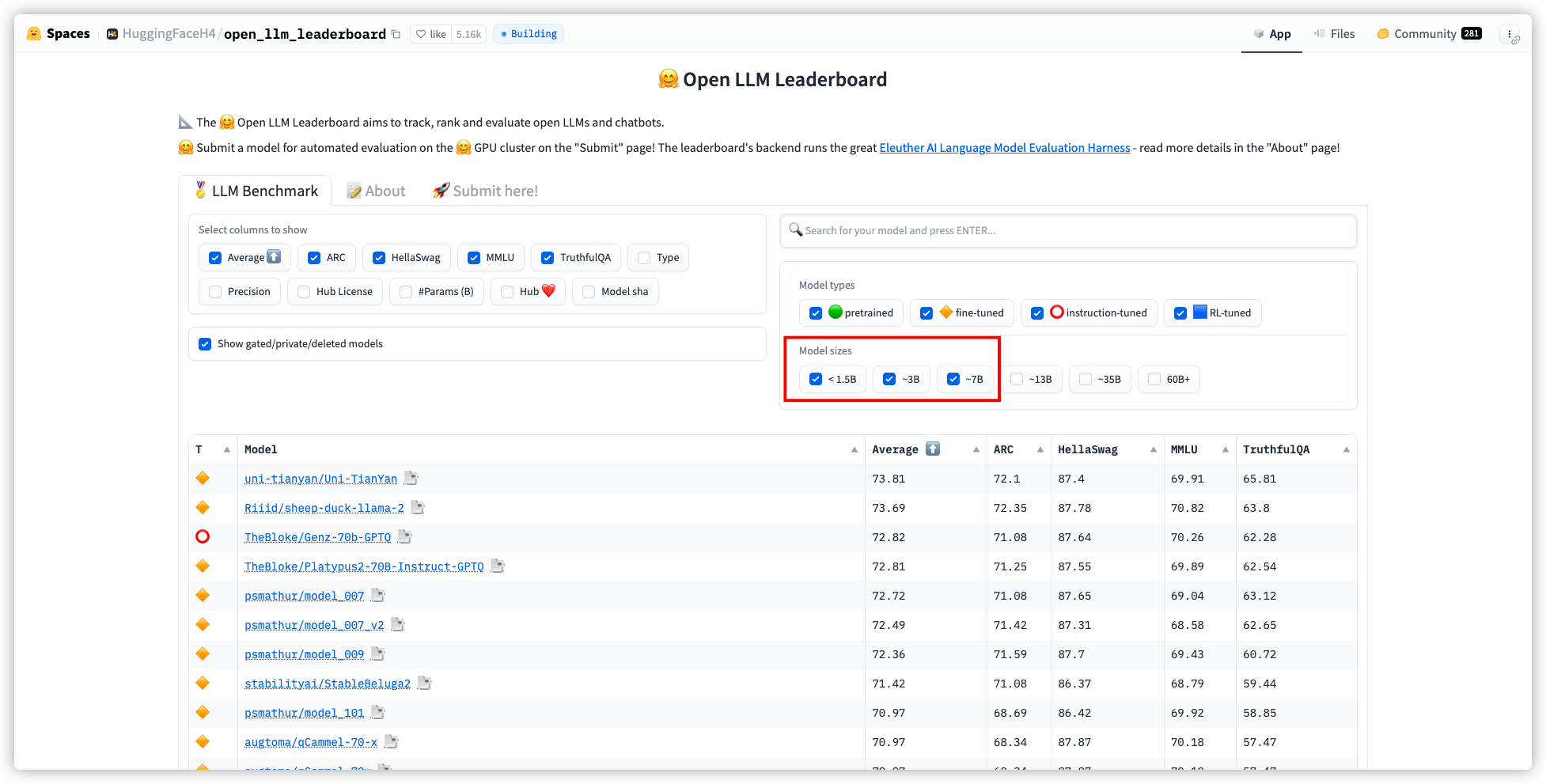
当然,LocalAI 是支持多模型文件的,你可以根据需要下载多个模型文件
关于模型这块,可以看官方文档:https://localai.io/models/
运行
如果你在浏览器中直接输入 http://群晖IP:8668,会返回 404 错误
1 | {"error":{"code":404,"message":"Cannot GET /","type":""}} |
因为 LocalAI 提供的是 REST API 接口,而不是网页。所以有 2 种方式来测试验证我们安装的服务是否成功,一种是使用 API 调试工具,另一种是用命令行
API 工具
这类工具很多,例如: Postman、Apifox、ApiPost等等,具体用什么关系不大,因为基本上主要功能是差不多的,老苏目前是用的是 Apifox
- 打开应用程序并创建一个新的请求
- 在请求的
URL字段中输入:http://192.168.0.197:8668/v1/completions - 设置请求方法为
POST - 在请求头部 (
Headers) 部分中添加一个新的头部,键为Content-Type,值为application/json - 在请求体 (
Body) 部分中选择raw选项,并将下面的JSON数据复制粘贴到请求体中:
1 | { |
- 确认您的请求已设置正确后,点击发送按钮以发送请求。
其中:
model:指定要使用的特定语言模型;prompt:用于指定生成文本的起始提示或开头文本。也就是你要提的问题;temperature:用于控制生成文本的多样性。temperature值越高,生成的文本越随机和多样化,但可能会牺牲一些准确性。相反,temperature值越低,生成的文本越保守和一致,更加符合模型的训练数据;
现在来聊个天,比如 how old are you?
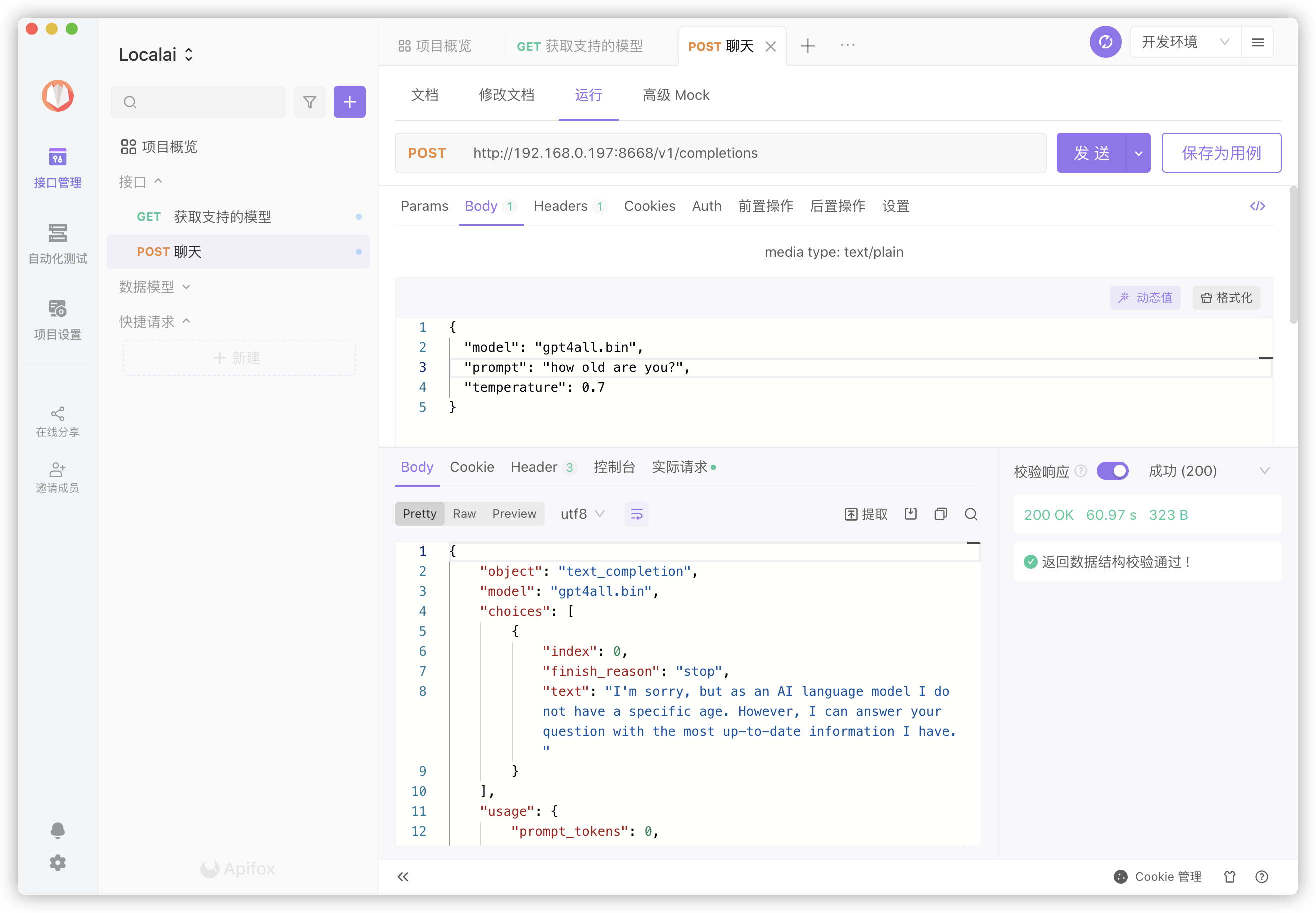
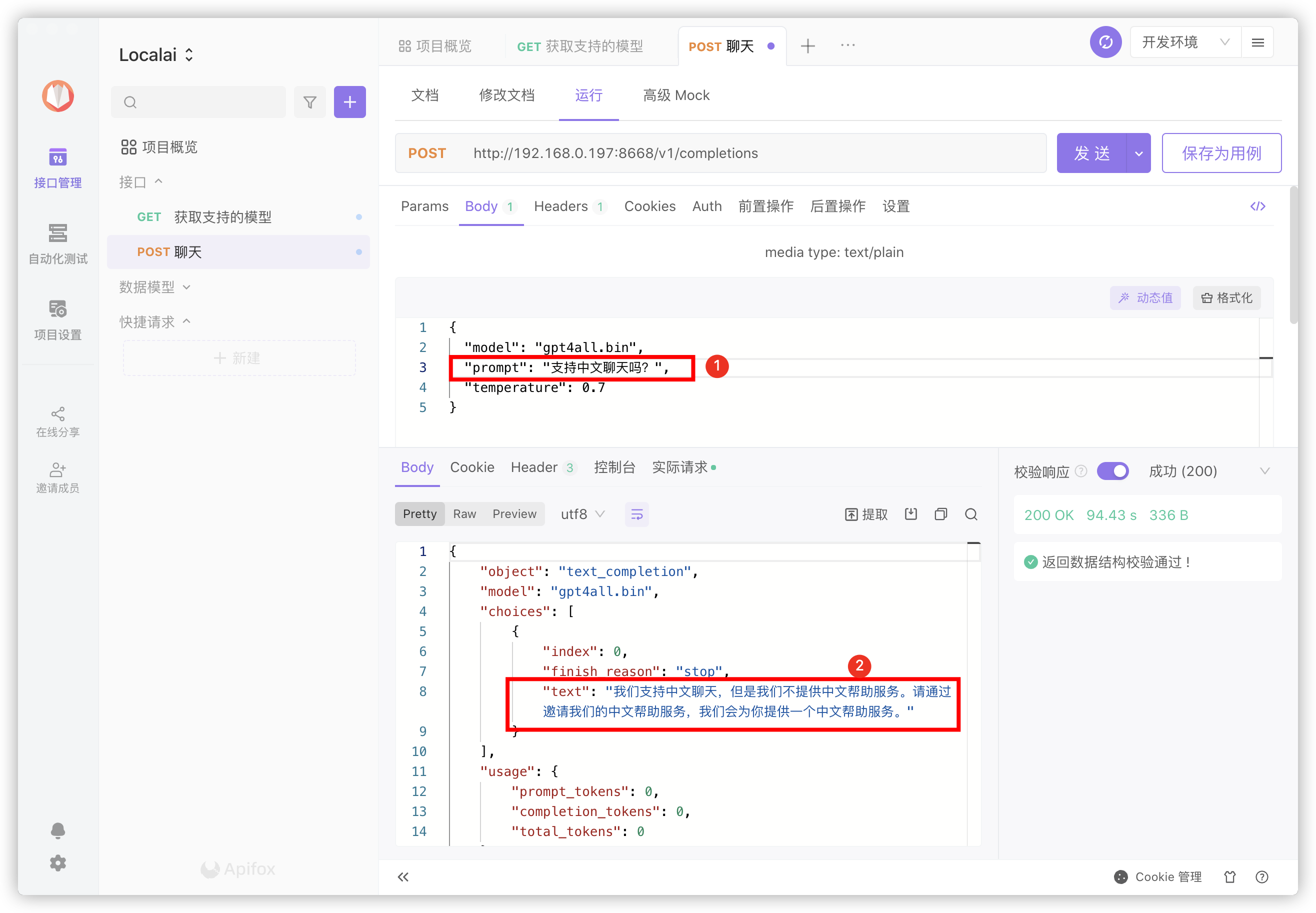
看看支不支持中文聊天?
提问只要修改
prompt后面的内容,回答看text后面的内容;
命令行
如果你不会 API 工具,用命令行也是可以的,用 SSH 客户端登录到群晖后,执行
1 | curl http://192.168.0.197:8668/v1/completions -H "Content-Type: application/json" -d '{ |
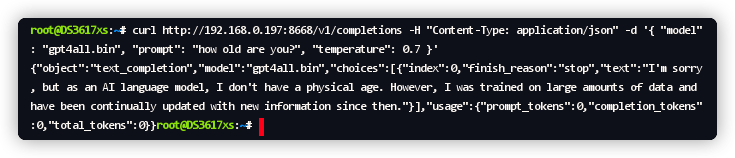
返回的结果在 https://www.json.cn 格式化之后
1 | { |
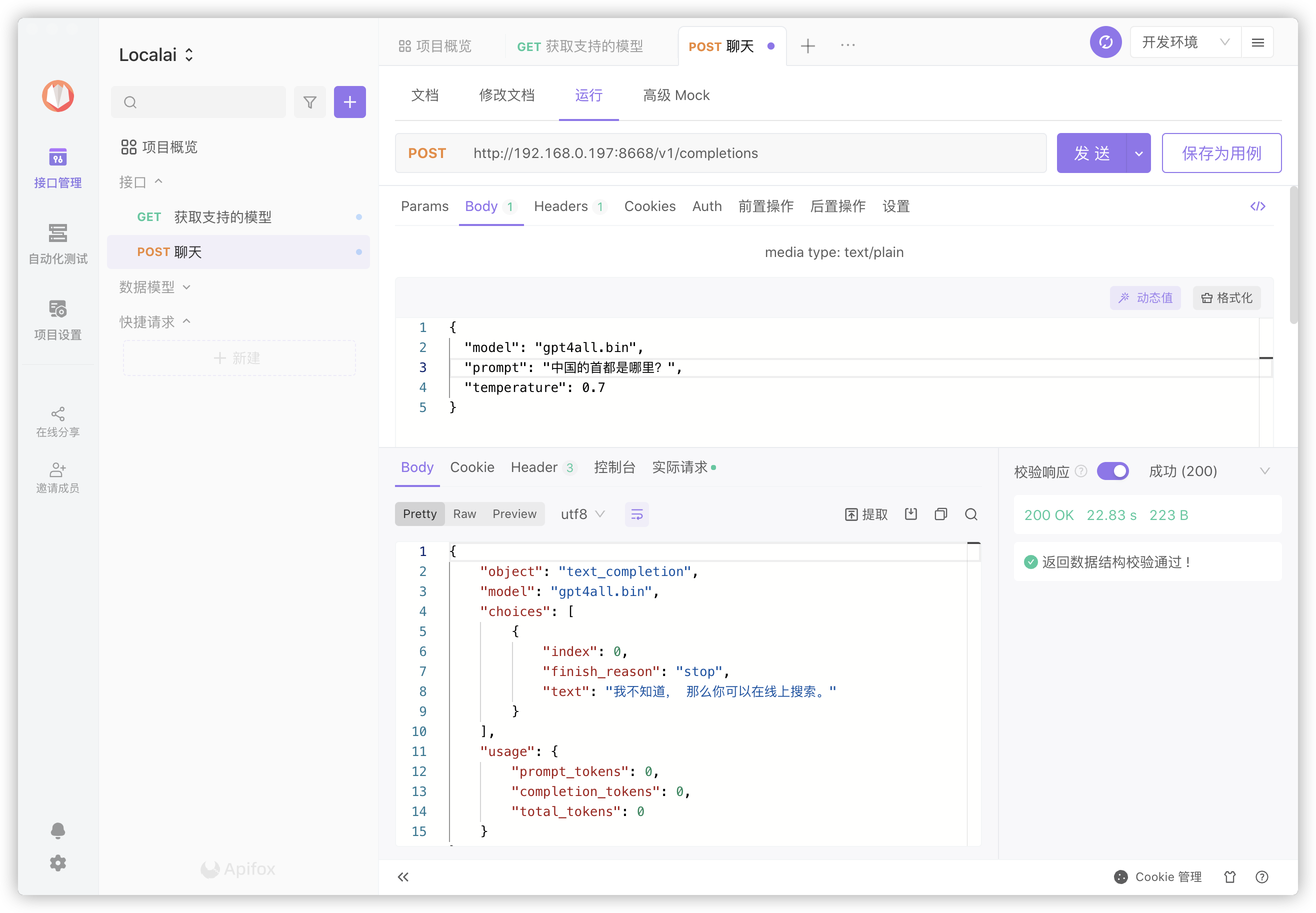
即便是同样的问题,每次的答复也是有区别的
1 | { |
小结
虽然老苏用的同一个模型文件,但是感觉上 LocalAI 比 Serge 要快一些,当然也可能是因为 618 升级了内存的缘故
参考文档
go-skynet/LocalAI: :robot: Self-hosted, community-driven, local OpenAI-compatible API. Drop-in replacement for OpenAI running LLMs on consumer-grade hardware. Free Open Source OpenAI alternative. No GPU required. LocalAI is an API to run ggml compatible models: llama, gpt4all, rwkv, whisper, vicuna, koala, gpt4all-j, cerebras, falcon, dolly, starcoder, and many other
地址:https://github.com/go-skynet/LocalAILocalAI :: LocalAI documentation
地址:https://localai.io/🖼️ 模型库 :: LocalAI 文档
地址:https://localai.io/models/