
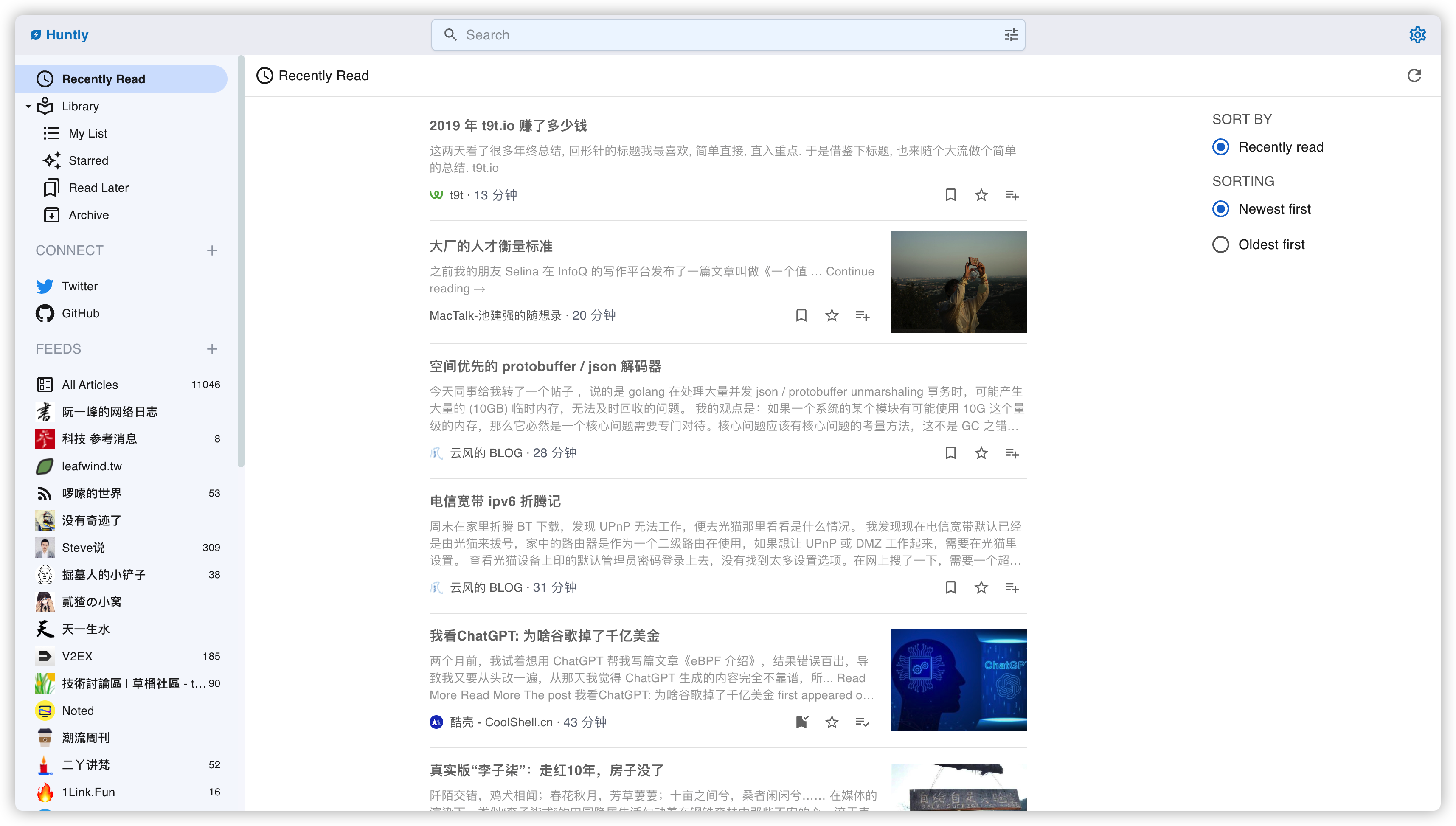
Huntly让信息管理更高效
本文软件由网友
Juijote推荐;
什么是 Huntly ?
Huntly是一个自托管的信息管理工具,简单来说,它包含以下功能:
RSS订阅和阅读。- 自动保存浏览过的网页,随后以保存、稍后读、收藏或存档的方式将其保存。
- 针对推特网站有特殊的处理,会自动保存请求过的推特
timeline,记录是否浏览过,在huntly中你甚至可以用更方便的方式重新查看这些推文。- 可以从标题、内容、类型、收藏方式等维度进行搜索。
- 连接其他服务,目前支持
GitHub,所以它也是一个Github stars管理工具。- 未来可能会支持连接到
Hypothesis等服务。
官方提供了演示站点,这里有很多不错的订阅,值得一看,比较可惜的是只有 opml 文件的导入,而没有导出功能
地址:http://huntly.rom666.com:8000/
账号:
demo密码:huntlydemo
安装
在群晖上以 Docker 方式安装。
在注册表中搜索 huntly ,选择第三个 lcomplete/huntly,双击直接下载
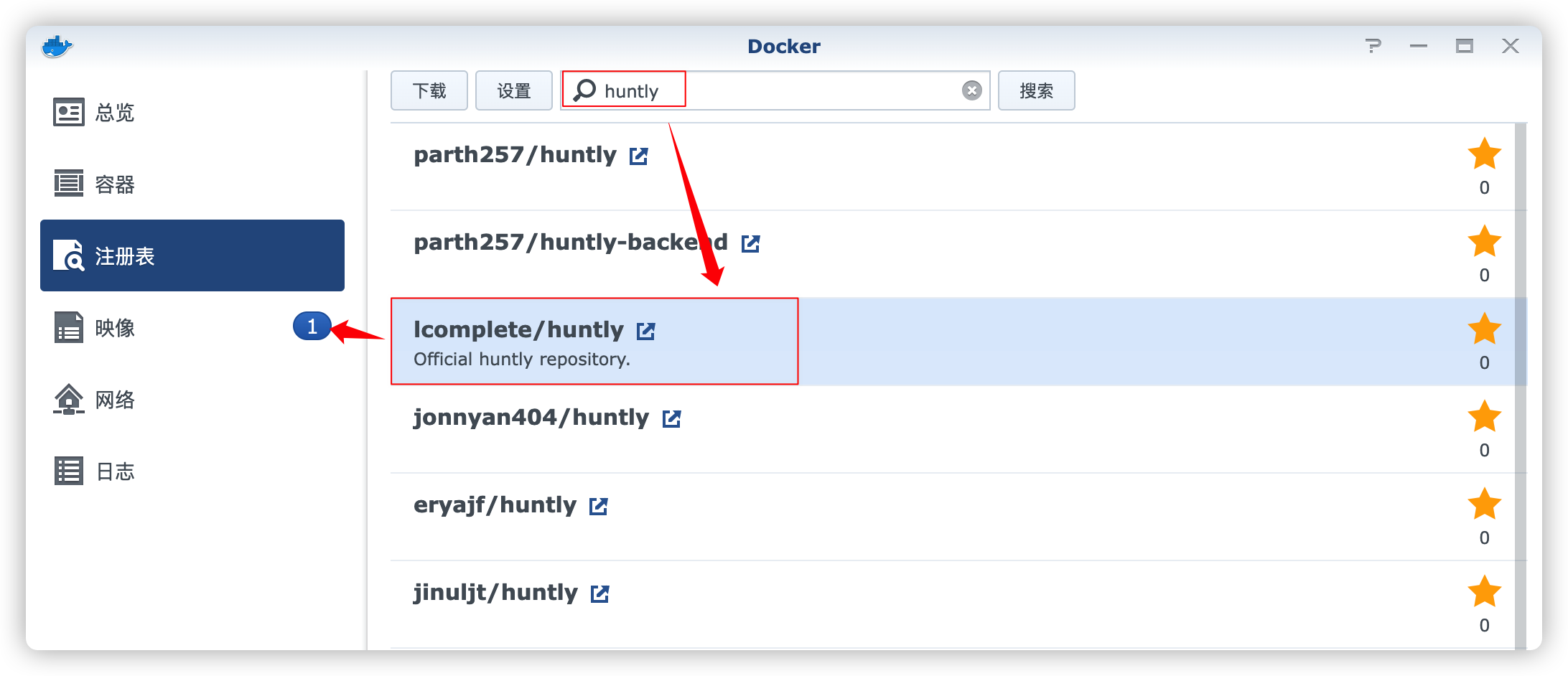
老苏折腾时, huntly只有一个版本,就是 0.1.0
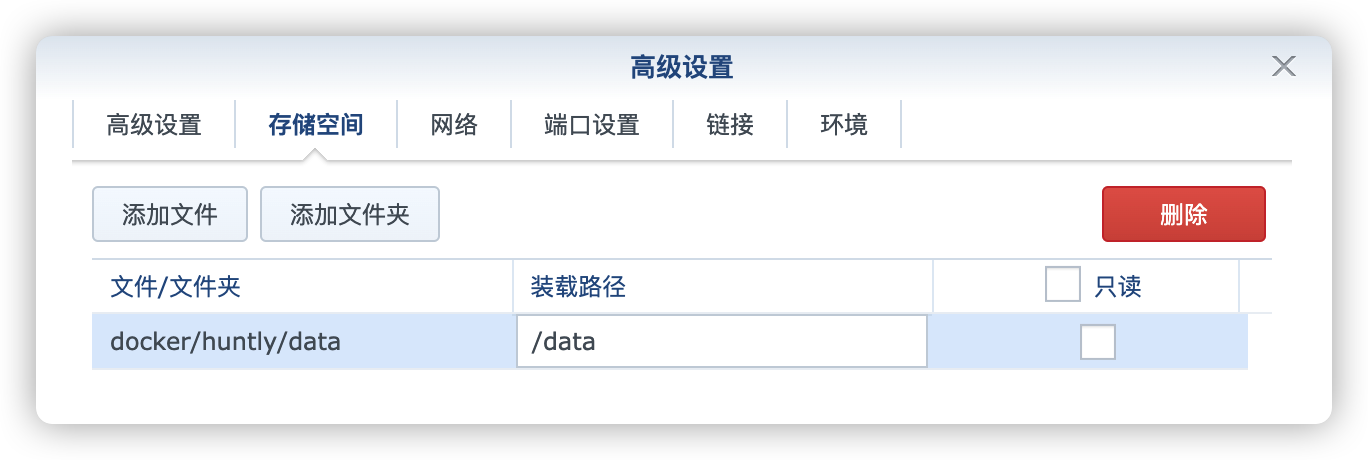
卷
在 docker 文件夹中,创建一个新文件夹 huntly,并在其中建一个子文件夹 data
| 文件夹 | 装载路径 | 说明 |
|---|---|---|
docker/huntly/data |
/data |
存放设置 |
端口
本地端口不冲突就行,不确定的话可以用命令查一下
1 | # 查看端口占用 |
| 本地端口 | 容器端口 |
|---|---|
3232 |
80 |
默认暴露了 2 个端口
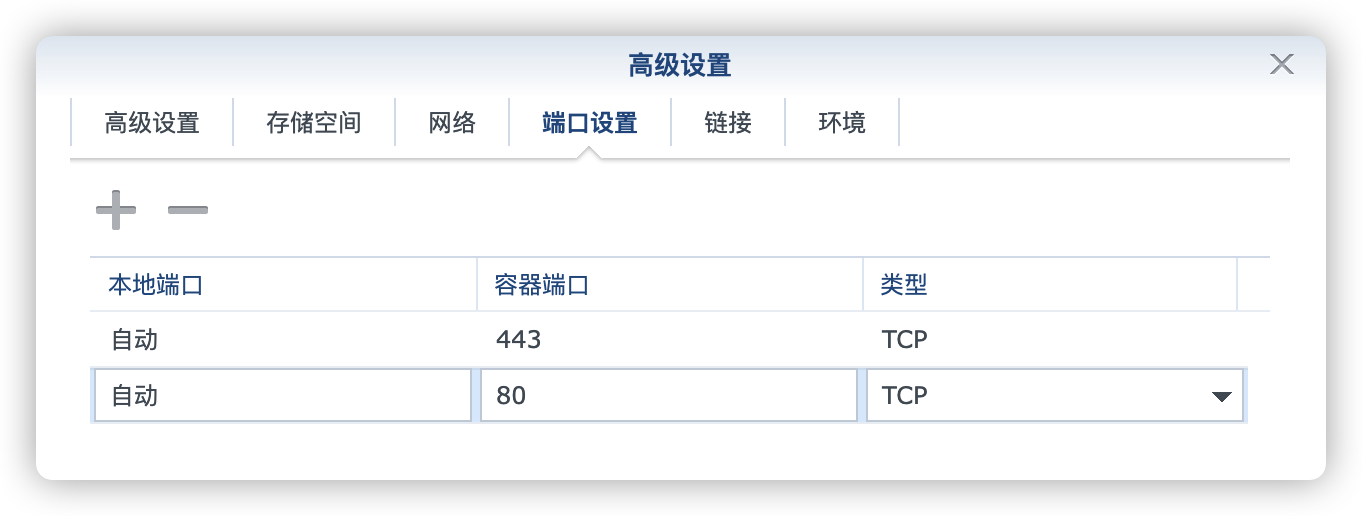
因为老苏用 npm 反代,所以只保留了 80 端口
顺便说一句,反代没发现有什么特殊的地方

命令行安装
如果你熟悉命令行,可能用 docker cli 更快捷
1 | # 新建文件夹 huntly 和 子目录 |
也可以用 docker-compose 安装,将下面的内容保存为 docker-compose.yml 文件
1 | version: '3' |
然后执行下面的命令
1 | # 新建文件夹 huntly 和 子目录 |

稳定之后,cpu 会降下来,主要是内存

运行
在浏览器中输入 http://群晖IP:3232 ,第一次首先需要创建一个管理员账号
【注意】:目前
Huntly仅支持单用户
进入后台
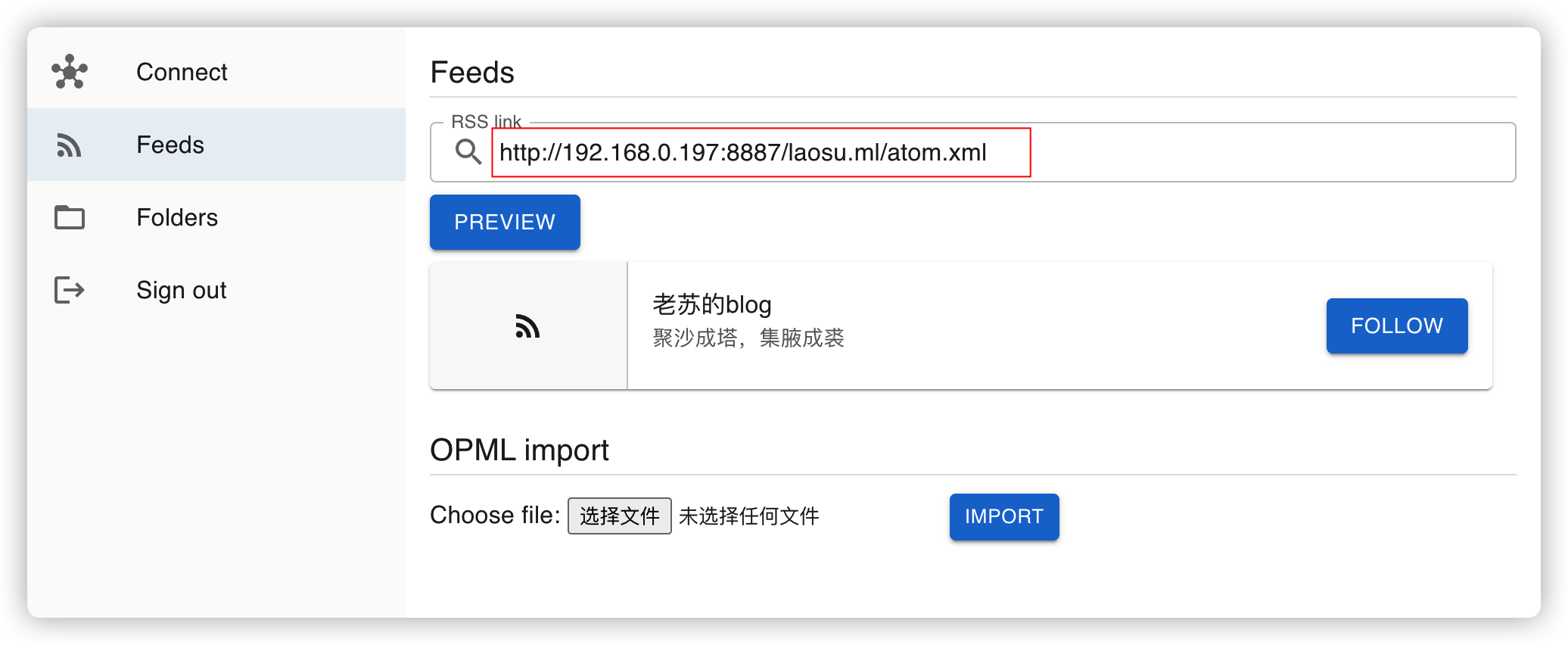
添加新的 feed
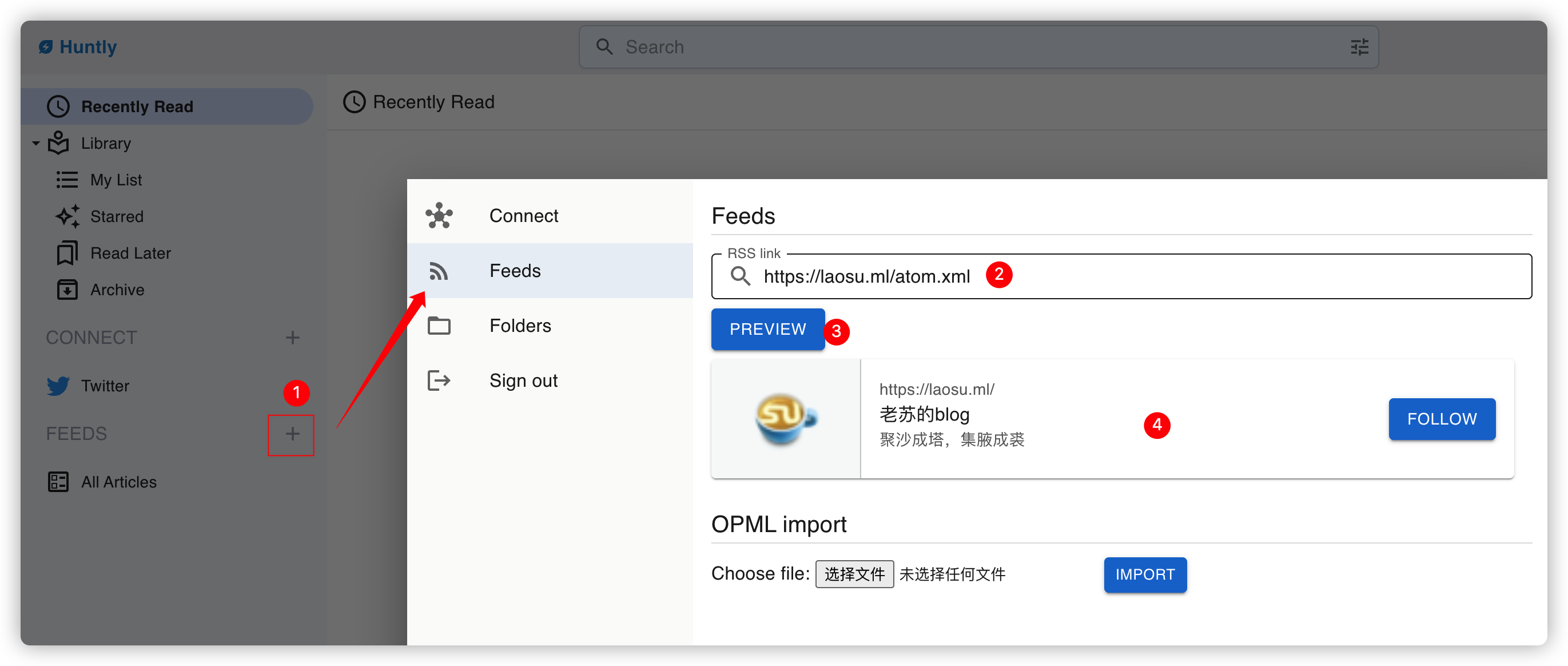
follow 成功后
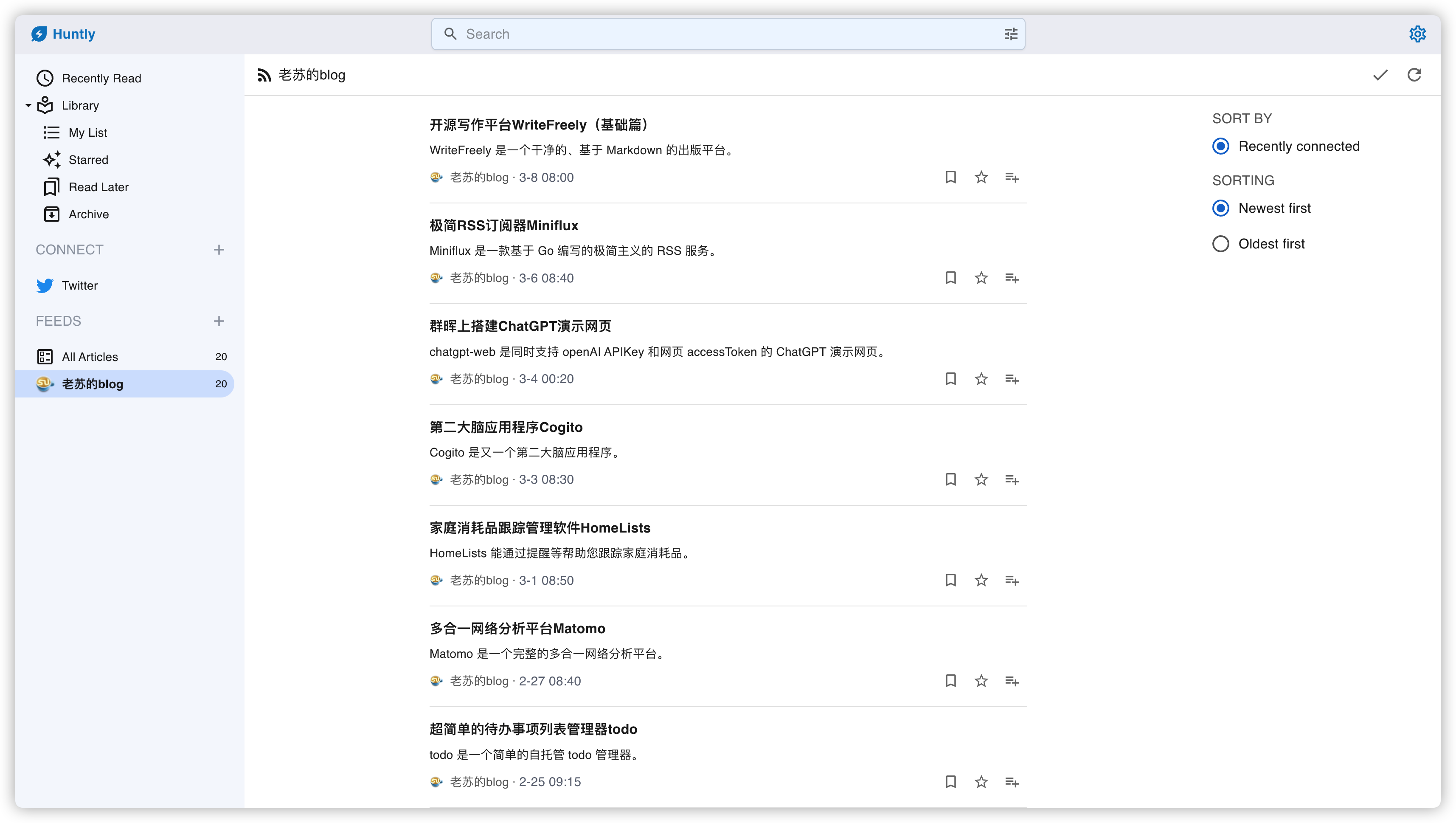
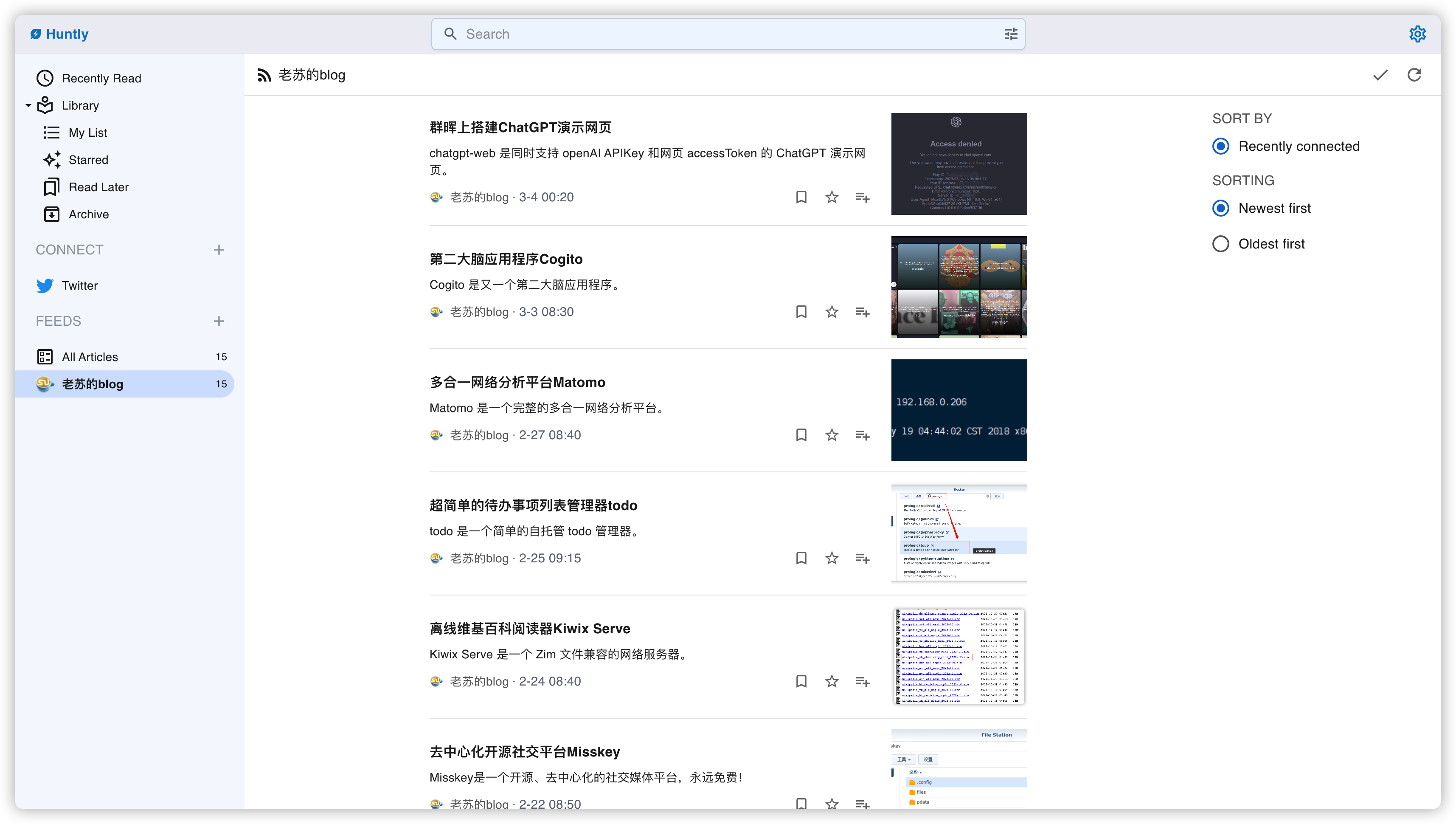
打开一篇
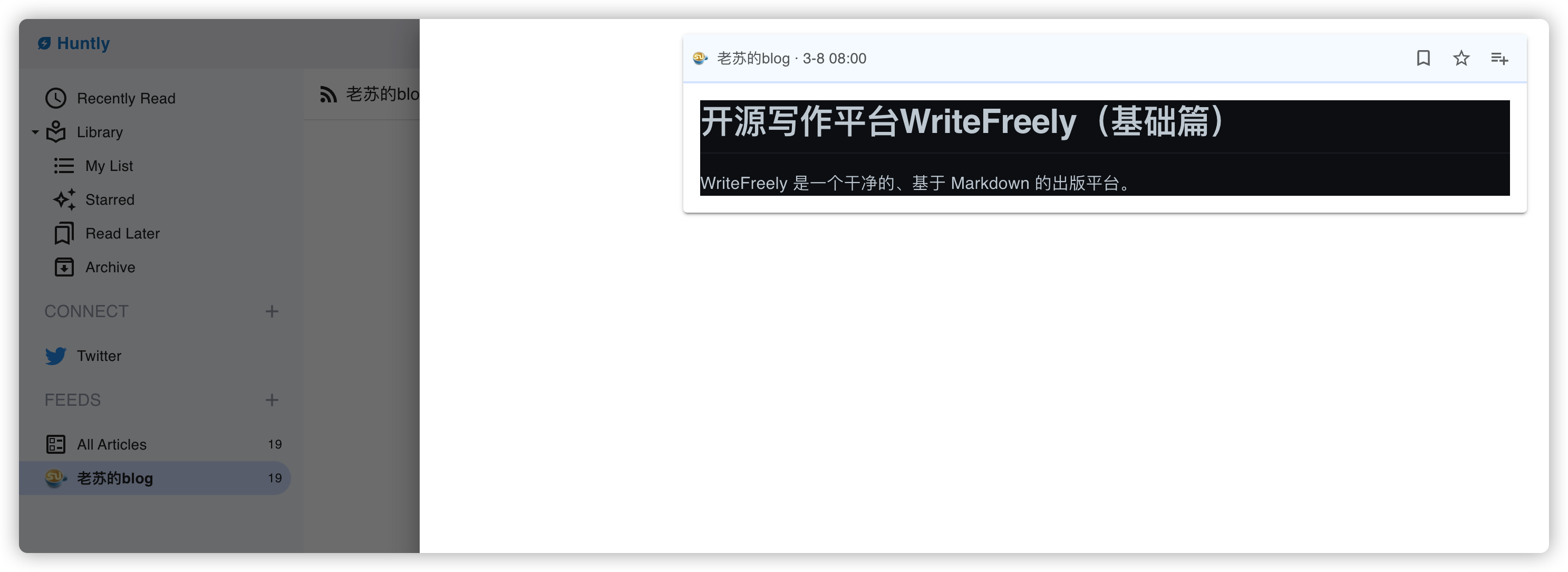
发现只是摘要
从设置中进入,你会发现默认情况下,Auto fetch full content 是没有启用的
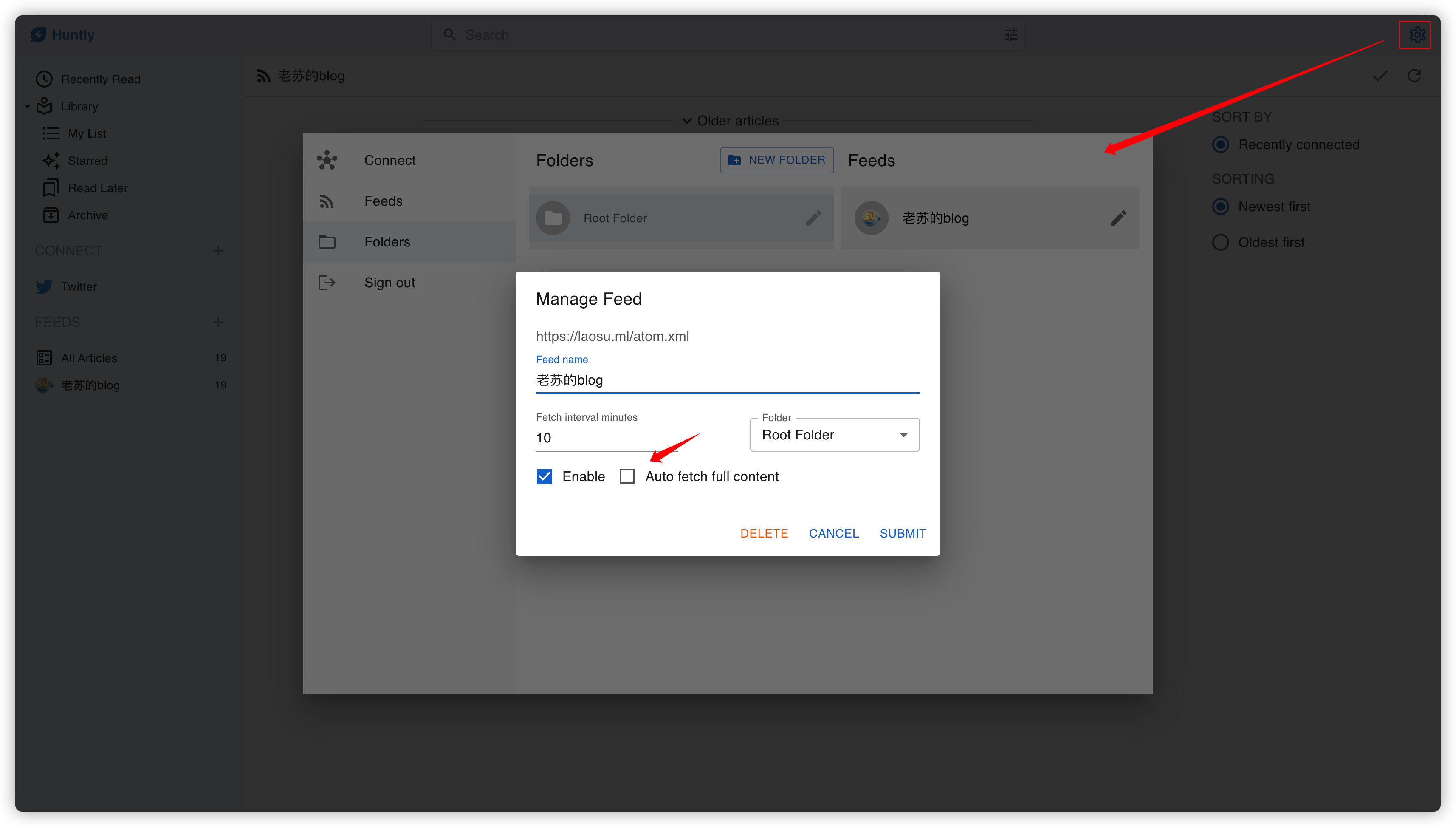
启用后稍等一会儿,先是图片出来了
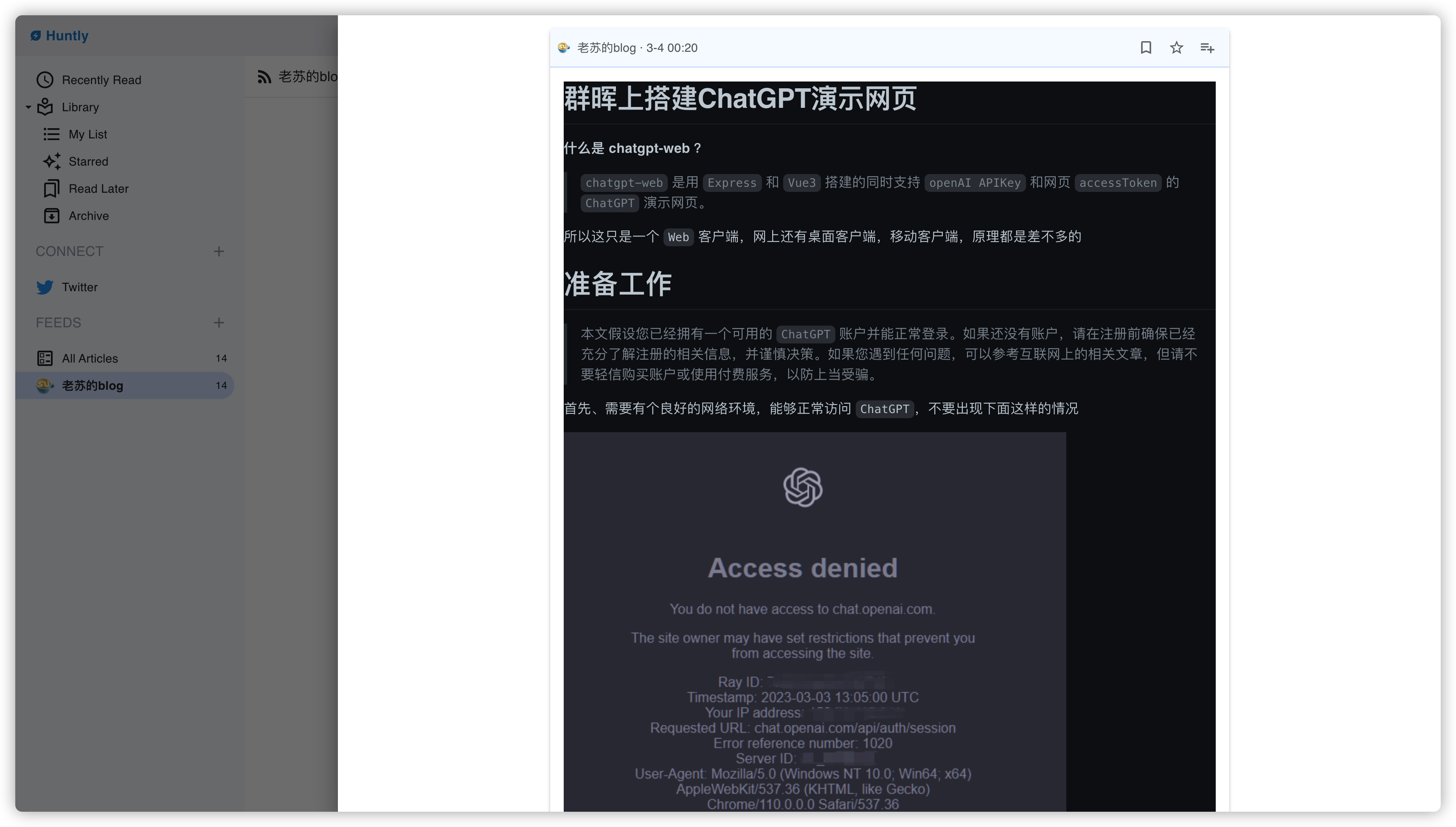
点击文章进入,已经是全文了
chrome 插件
插件目前还在开发中,尚未上架谷歌商店。
但这个插件作用不大,只是用于快速访问服务器,其作用类似一个书签;
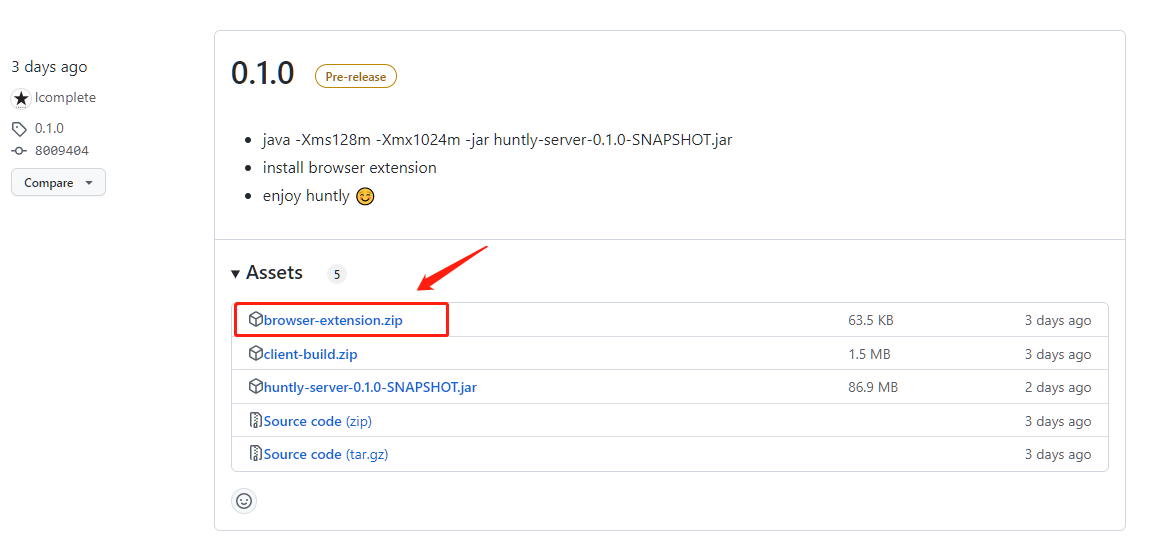
在 https://github.com/lcomplete/huntly/releases 页面下载 browser-extension.zip 文件
在浏览器中的 扩展程序 中,启用 开发者模式,加载已解包的扩展即可
安装好,还需要进行设置
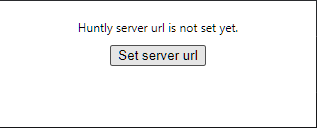
添加服务器地址
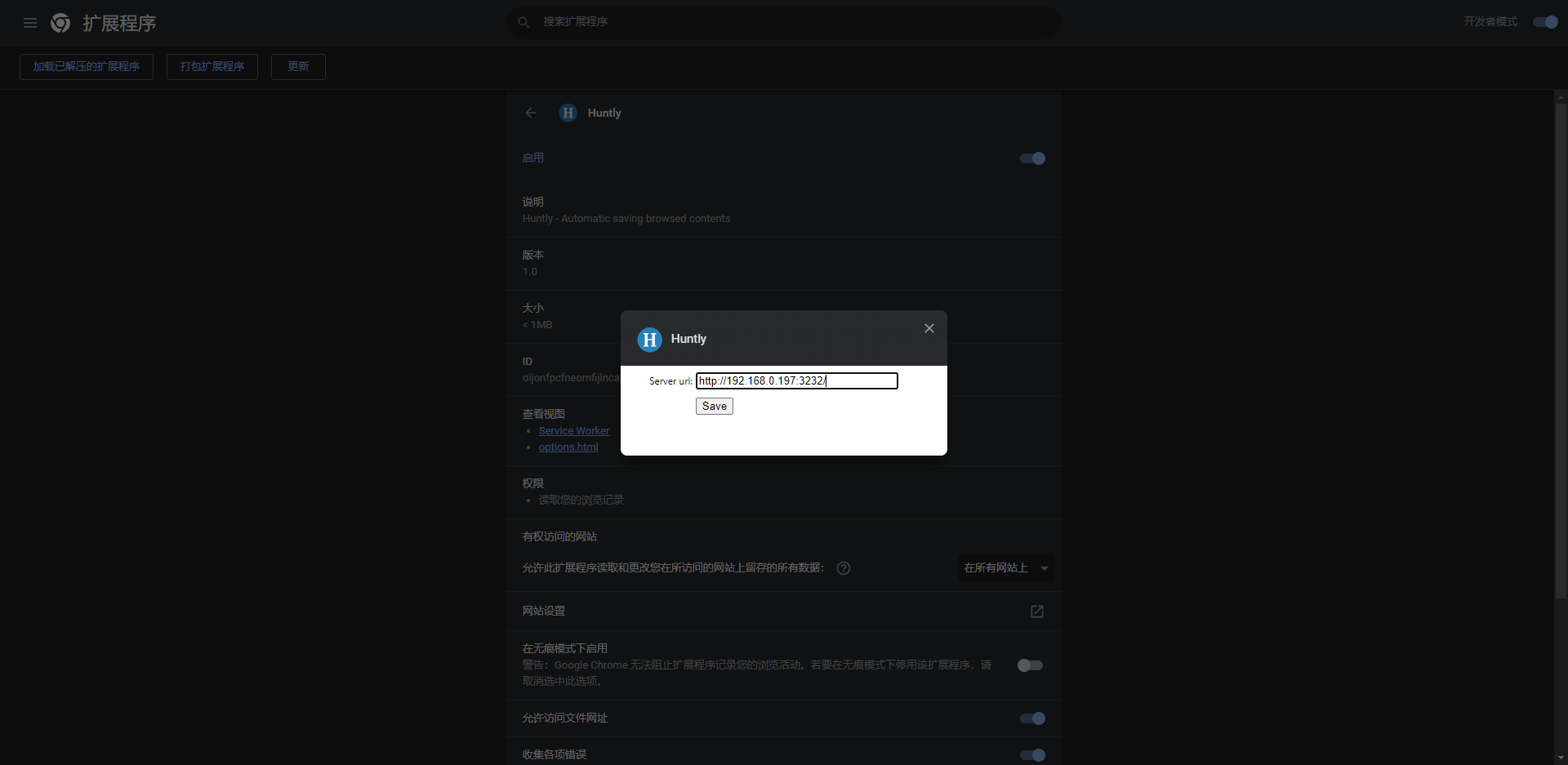
这个插件的作用就是打开服务器地址
参考文档
huntly/README.zh-CN.md at main · lcomplete/huntly
地址:https://github.com/lcomplete/huntly/blob/main/README.zh-CN.md